NLP Research & Projects
Key Research Contributions and System Implementations
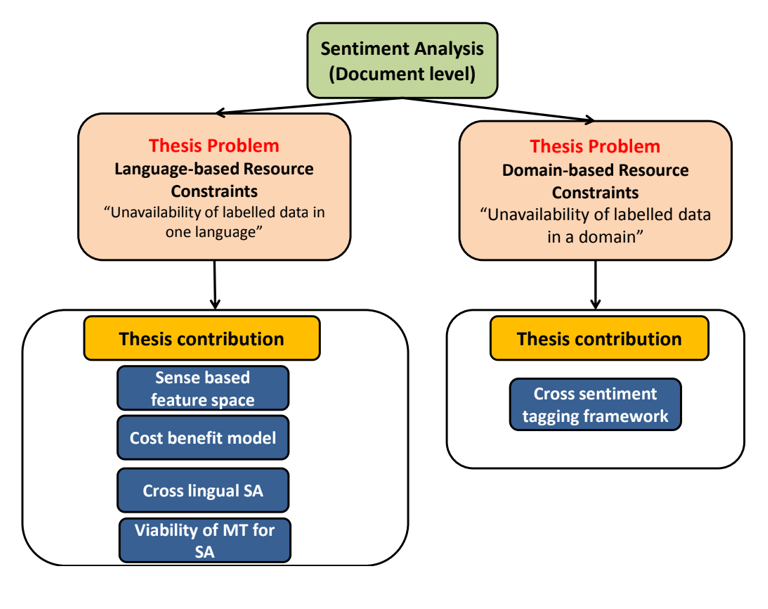
Sentiment Analysis under ResourceConstraints
The thesis tackles key challenges in multilingual Sentiment Analysis using innovative AI approaches, presenting novel solutions for resource-constrained scenarios in language and domain adaptation. The research introduces a wordnet sense-based method that outperforms traditional lexeme-based approaches, achieving significant accuracy improvements while reducing dimensionality. The work challenges conventional machine translation-based approaches for cross-lingual sentiment analysis, providing experimental evidence across multiple European and Indian languages, while introducing an economic model for annotation cost-benefit analysis. The research concludes with an effective approach for cross-domain sentiment adaptation using confidence-threshold based noise filtering, demonstrating practical solutions for building high-accuracy sentiment analysis systems in resource-limited environments.
Course: Text Mining and Social Media Analytics
Co-designed An advanced course that delves into the critical intersection of text mining, social media analytics, and artificial intelligence in the Web 2.0 era. This comprehensive program explores cutting-edge techniques for analyzing unstructured textual data from social media platforms, addressing key challenges such as content authenticity, community dynamics, and language processing complexities. The curriculum combines theoretical foundations with practical business applications, covering state-of-the-art text mining methods, network analysis models, and emerging AI systems. Students gain expertise in evaluating technological limitations, understanding business requirements for text processing applications, and critically assessing the societal impact of these technologies. The course equips future professionals with the knowledge to develop and implement sophisticated text analytics solutions while maintaining a balanced perspective on both the potential and limitations of current technological capabilities in the field.


The Haves and the Have-Nots: Leveraging Unlabelled Corpora for Sentiment Analysis
Expensive feature engineering based on WordNet senses has been shown to be useful for document level sentiment classification. A plausible reason for such a performance improvement is the reduction in data sparsity. However, such a reduction could be achieved with a lesser effort through the means of syntagma based word clustering. In this paper, the problem of data sparsity in sentiment analysis, both monolingual and cross-lingual, is addressed through the means of clustering. Experiments show that cluster based data sparsity reduction leads to performance better than sense based classification for sentiment analysis at document level. Similar idea is applied to Cross Lingual Sentiment Analysis (CLSA), and it is shown that reduction in data sparsity (after translation or bilingual-mapping) produces accuracy higher than Machine Translation based CLSA and sense based CLSA.

